En sistemas operativos, el bloqueo mutuo (también conocido como interbloqueo, traba mortal, deadlock, abrazo mortal) es el bloqueo permanente de un conjunto de procesos o hilos de ejecución en un sistema concurrente que compiten por recursos del sistema o bien se comunican entre ellos. A diferencia de otros problemas de concurrencia de procesos, no existe una solución general para los interbloqueos.
Todos los interbloqueos surgen de necesidades que no pueden ser satisfechas, por parte de dos o más procesos. En la vida real, un ejemplo puede ser el de dos niños que intentan jugar al arco y flecha, uno toma el arco, el otro la flecha. Ninguno puede jugar hasta que alguno libere lo que tomó.
En el siguiente ejemplo, dos procesos compiten por dos recursos que necesitan para funcionar, que sólo pueden ser utilizados por un proceso a la vez. El primer proceso obtiene el permiso de utilizar uno de los recursos (adquiere el lock sobre ese recurso). El segundo proceso toma el lock del otro recurso, y luego intenta utilizar el recurso ya utilizado por el primer proceso, por lo tanto queda en espera. Cuando el primer proceso a su vez intenta utilizar el otro recurso, se produce un interbloqueo, donde los dos procesos esperan la liberación del recurso que utiliza el otro proceso.

Condiciones necesarias[editar]
También conocidas como condiciones de Coffman por su primera descripción en 1971 en un artículo escrito por E. G. Coffman.
Estas condiciones deben cumplirse simultáneamente y no son totalmente independientes entre ellas.
Sean los procesos P0, P1, ..., Pn y los recursos R0, R1, ..., Rm:
- Condición de exclusión mutua: existencia de al menos de un recurso compartido por los procesos, al cual sólo puede acceder uno simultáneamente.
- Condición de retención y espera: al menos un proceso Pi ha adquirido un recurso Ri, y lo retiene mientras espera al menos un recurso Rj que ya ha sido asignado a otro proceso.
- Condición de no expropiación: los recursos no pueden ser expropiados por los procesos, es decir, los recursos sólo podrán ser liberados voluntariamente por sus propietarios.
- Condición de espera circular: dado el conjunto de procesos P0...Pm(subconjunto del total de procesos original),P0 está esperando un recurso adquirido por P1, que está esperando un recurso adquirido porP2,... ,que está esperando un recurso adquirido por Pm, que está esperando un recurso adquirido por P0. Esta condición implica la condición de retención y espera.

Evitando bloqueos mutuos[editar]
Los bloqueos mutuos pueden ser evitados si se sabe cierta información sobre los procesos antes de la asignación de recursos. Para cada petición de recursos, el sistema controla si satisfaciendo el pedido entra en un estado inseguro, donde puede producirse un bloqueo mutuo. De esta forma, el sistema satisface los pedidos de recursos solamente si se asegura que quedará en un estado seguro. Para que el sistema sea capaz de decidir si el siguiente estado será seguro o inseguro, debe saber por adelantado y en cualquier momento el número y tipo de todos los recursos en existencia, disponibles y requeridos. Existen varios algoritmos para evitar bloqueos mutuos:
- Algoritmo del banquero, introducido por Dijkstra.
- Algoritmo de grafo de asignación de recursos.
- Algoritmo de Seguridad.
- Algoritmo de solicitud de recursos.


Prevención
Los bloqueos mutuos pueden prevenirse asegurando que no suceda alguna de las condiciones necesarias vistas anteriormente.
- Eliminando la exclusión mutua: ningún proceso puede tener acceso exclusivo a un recurso. Esto es imposible para procesos que no pueden ser encolados (puestos en un spool), e incluso con colas también pueden ocurrir interbloqueos.
- La condición de posesión y espera puede ser eliminada haciendo que los procesos pidan todos los recursos que van a necesitar antes de empezar. Este conocimiento por adelantado muchas veces es imposible nuevamente. Otra forma es requerir a los procesos liberar todos sus recursos antes de pedir todos los recursos que necesitan. Esto también es poco práctico en general.
- La condición de no expropiación puede ser también imposible de eliminar dado que un proceso debe poder tener un recurso por un cierto tiempo o el procesamiento puede quedar inconsistente.
- La condición de espera circular es la más fácil de atacar. Se le permite a un proceso poseer sólo un recurso en un determinado momento, o una jerarquía puede ser impuesta de modo tal que los ciclos de espera no sean posibles.











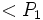 ,...,
,..., 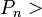 , donde para un proceso
, donde para un proceso 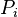 , el pedido de recursos puede ser satisfecho con los recursos disponibles sumados los recursos que están siendo utilizados por
, el pedido de recursos puede ser satisfecho con los recursos disponibles sumados los recursos que están siendo utilizados por 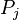 , donde j < i. Si no hay suficientes recursos para el proceso
, donde j < i. Si no hay suficientes recursos para el proceso  i+1 puede tomar los recursos que necesite, y así sucesivamente. Si una secuencia de este tipo no existe, el sistema se dice que está en un estado inseguro, aunque esto no implica que esté bloqueado.
i+1 puede tomar los recursos que necesite, y así sucesivamente. Si una secuencia de este tipo no existe, el sistema se dice que está en un estado inseguro, aunque esto no implica que esté bloqueado.